Audio Post, along with Visual Effects, have benefited greatly from innovative ML-based tools. There are tools on the horizon for voice cloning, isolating voices from the sound of a crowd, and automated mixing. More challenging are automated music composition and voice overs, which are rapidly getting ready for Prime Time. They’re not there yet, but as I mentioned in Amplifying Production, automated voice overs are ready for education/training and even corporate production.
Fully automated “radio” (audio only) news is on the horizon. These ML tools will take a basic data feed from a sports-ball game, for example, and format it into an article, that is then “read” by a ML voice over. I doubt it will be long before that research and BBC Research’s synthetic newsreader merge! Listeners, or viewers, would never know there wasn’t a human involved.
With all the attendant ethical complications, voice cloning will forever end the need for “frankenbites.” Voice cloning once needed large samples of a voice before it could synthesize new words, but now requires less than a minute of the sample voice to accurately create new words in that voice. It doesn’t provide any visuals, but that’s only a temporary setback
Much more complex than the technology are the ethical issues. The ability to reliably create words in someone’s voice, words they never said, is very open to abuse. Even in the context of Frankenbites, how far is “fixing” the line, and where does outright fake take over?
It’s not only audio voices that are being fakes, deepfakes create a compelling, but fake, visual of a person. Much more on deepfakes later.
Also interesting to note, is that many of these technologies are now mature enough that there are open source versions, so programmers can add it to their apps.
Automated Mixing
No-one is suggesting that any machine is going to be finalizing the mix on any production, but there is a field of research that is studying Intelligent Mixing Systems that seeks to understand how a mixer authors content to decide what parts can be automated to some extent to “improve the efficiency of the people involved in content creation in terms of leveraging some of their production tools using AI.” Translate that to the language of this article and they’re talking about Amplifying the mixer.

In a late April 2021 article for SMPTE AI for Audio Content Creation Michael Goldman mostly discusses the feasibility of automated mixing:
Sunil Bharitkar, principal research scientist for AI research at Samsung Electronics, points to a recent article titled “Context-Aware Intelligent Mixing Systems” in the Journal of the Audio Engineering Society (AES) penned by European researchers that addresses so-called Intelligent Mixing Systems (IMS). The article suggests that human creative skill and AI tools could potentially co-exist nicely as long as context is factored into the collaboration, meaning human decision-making needs to be essentially the controlling factor in how, when, and to what degree IMS technology is used in the creative process.
The same group penned a second article on one approach to intelligent music production tools aided by ML—in this case, the potential for a deep neural network to automate much of the process of creating drum mixes.
It’s only a research project, but – once again – the goal is to amplify the creative, not replace them.
Synthetic Voiceovers
One part of ML’s inroads into post production that is threatening employment, is the explosion of text-to-speech generators that are being pitched as human replacements. The technology grew form the more familiar text-to-speech we hear every day on our phones.
Long term iPhone users will appreciate the progressive improvements over the years of the Siri voice(s). The most recent versions are good, but easily spotted as text-to-speech. We use the macOS System voices for temp voiceover in the Lumberjack Builder NLE, but we have no pretensions they’re anything but an alternative to recording your own voice.
The Siri voices are built from samples of the human voice extracted from hours of recordings. You know what else is good at examining lots of examples and creating a model? If you said “Machine Learning” you’d be right.
These days my my Facebook feed is full of ads for Talkia, Speechelo. Speechor and others. The results, of some, are way better than expected. Of those I listened to I found Speechelo more natural and I could definitely use that quality for short training videos. I’m sure everyone would agree that it would be an improvement on recording myself!

Natural Reader was highly regarded in one article I read, but I didn’t find all that natural. To me, Speechelo is the least obviously fake.
These synthetic voiceovers are only going to get better as research continues. The current state-of-the-art would be sufficient for product demos and training videos. Combine with a synthetic human and you have Synthesia. Perfectly useful In the corporate world.
Voice Cloning
Voice Cloning generates a synthetic human voice that has very little difference from the human it was sampled from. In practical terms, that means someone could take a few seconds of my recorded voice, and then put whatever words they like ‘in my mouth’. It’s very useful for correcting simple errors, as in the Descript editor, but has some serious ethical implications when you’re cloning someone else’s voice.
It’s such a useful tool that Descript spent a good chunk of their $15 million A series funding on buying Lyrebird. Lyrebird was incorporated as Overdub in Descript’s online editor. In the Descript editor you can re-voice yourself as simply as typing in the replacement words.
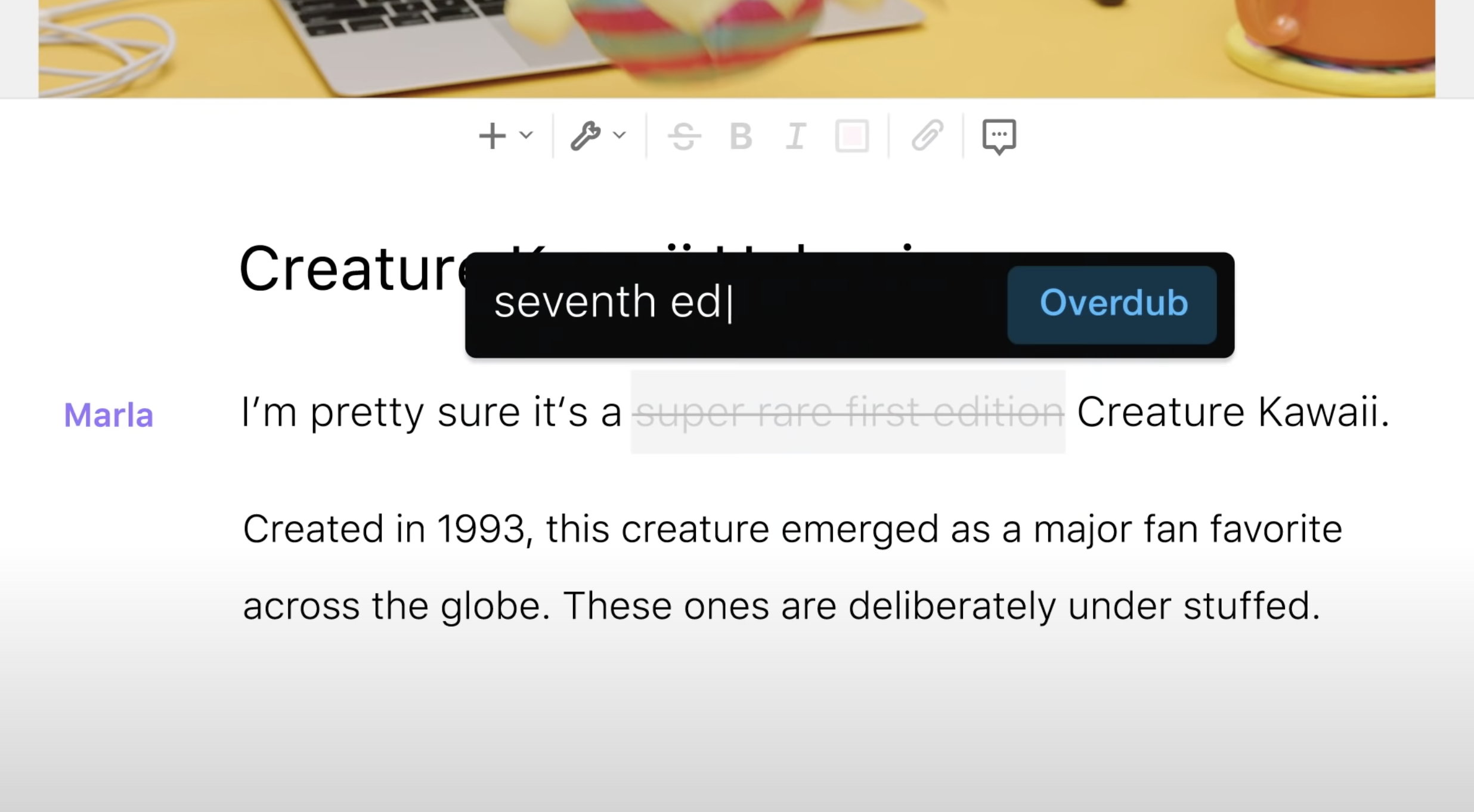
If you combine Voice Cloning, mouth morphing (already used in several examples yet to come) and some existing video of me, I could seem to be saying the most outrageous things, even if no word of it ever left my mouth under my control! Until recently, ethical issues were diminished by the need to have hours of recordings of the source voice in order to successfully clone.
Modern voice cloning requires only a few seconds sample, which is why it can work in Descript.
No mainstream NLE has included an Overdub-like feature, but if you feel like creating your own, you’ll need a few seconds of the voice to sample and this GitHub project.
Real-Time-Voice-Cloning SV2TTS is a three-stage deep learning framework that allows to create a numerical representation of a voice from a few seconds of audio, and to use it to condition a text-to-speech model trained to generalize to new voices.
Research continually finds ways to improve cloned voices. In January 2021 Cornell published a research paper i on their research into more expressive voice cloning.
Any attempt at automatic translation of movies into foreign languages – a subject covered in more detail later in the article – has to involve voice cloning.
Music Composition
In my 2017 AI and Production: Overview article I wrote of Jukedeck’s music composition learning machine. Most ML examines large numbers of examples and “works out for itself” how to do what you want it to do. Their methodology is hidden behind a paywall, but Jukedeck progressed dramatically between this example from 2014, and this one from just two years later in 2016. From bad 80’s game music to music good enough for background tracks or maybe a health or retirement commercial!
Jukedeck 2.0 became a commercial product offering custom music tracks, but is sadly no longer with us. Research goals moved from simply wanting the machine to compose music, to wanting Aiva to become one of the greatest composers in history! Aiva stands for for Artificial Intelligence Virtual Artist.
That’s a bold ambition but listen to some of the examples before you judge. I’ve definitely heard worse in some library collections!
Like Jukedeck before it, Aiva is a commercial, custom soundtrack creation tool that’s free for non-profit projects. In Richter Studio’s excellent AI and the Next Decade of Video Productionreports of another custom music startup Amper.
Amper, a new startup that recently raised $4 million in funding and also offers music created by AI. Amper’s focus is to empower users to “instantly create and customize original music for your content.”
Per their website, Amper claims that “Your music is uniquely crafted with no risk of it being used by someone else.” Even better, the site also states that “Amper provides you with a global, perpetual-use, and royalty-free license, with no conditional or unexpected financial expenses.”
https://www.ampermusic.com/
While the best attempt at an AI musical were “as pleasant as a milky drink”, background music composition by machine equals typical music library fare. And almost as if I had written their website, Aiva refers to itself as “A Creative Assistant for Creative People.”
Introduction, AI and ML, Amplified Creativity
- Introduction and a little history
- What is Artificial Intelligence and Machine Learning
- Amplified Creatives
- Can machines tell stories? Some attempts
- Car Commercial
- Science Fiction
- Music Video
- The Black Box – the ultimate storyteller
- Documentary Production
- Greenlighting
- Storyboarding
- Breakdowns and Budgeting
- Voice Casting
- Automated Action tracking and camera switching
- Smart Camera Mounts
- Autonomous Drones
Amplifying Audio Post Production
- Automated Mixing
- Synthetic Voiceovers
- Voice Cloning
- Music Composition
Amplifying Visual Processing and Effects
- Noise Reduction, Upscaling, Frame Rate Conversion and Colorization
- Intelligent Reframing
- Rotoscoping and Image Fill
- Aging, De-aging and Digital Makeup
- ML Color Grading
- Multilingual Newsreaders
- Translating and Dubbing Lip Sync
- Deep Fakes
- Digital Humans and Beyond
- Generating images from nothing
- Predicting and generating between first and last frames.
- Using AI to generate 3D holograms
- Visual Search
- Natural Language Processing
- Transcription
- Keyword Extraction
- Working with Transcripts
- We already have automated editing
- Magisto, Memories, Wibbitz, etc
- Templatorization
- Automated Sports Highlight Reels
- The obstacles to automating creative editing
Amplifying your own Creativity
- Change is hard – it is the most adaptable that survive
- Experience and practice new technologies
- Keep your brain young