While video dominates most communication and entertainment, it seems like Artificial Intelligence thrives on text. There’s a lot of new and quite diverse tools for using text prompts for image generation, 3D model creation, Human avatar movement, Animation and editing, all driven with text prompts. While text prompts are the current interface, they are not the end game. After all we already have, in various stages of development and availability.
Text to image
Text prompts generate images or modify existing images. There’s a certain skill in finding the right prompts, but they are fun to play with, and should help producers and customers “pre-visualize” what they want with one of these tools, then bring it to the artist as a “sketch” that conveys the direction the client wants the image to take. That’s got to be better than a verbal description. Examples are dall-E 2, mid journey, Stable Diffusion, Google Imagen

Text to 3D Model
Recently announced DreamFusion uses similar AI techniques to the image generation tools, with the goal of creating 3D models. The results are encouraging, but perhaps not as advanced as some of the other techniques.
Text to movement
Claiming “natural and expressive human motion generation” MDM: Human Motion Diffusion Model, uses text to direct 3D avatars in a 3D environment. There demo video is very impressive. They should definitely get together with Synthesis.io who are starting research into moving 3D avatars through space.
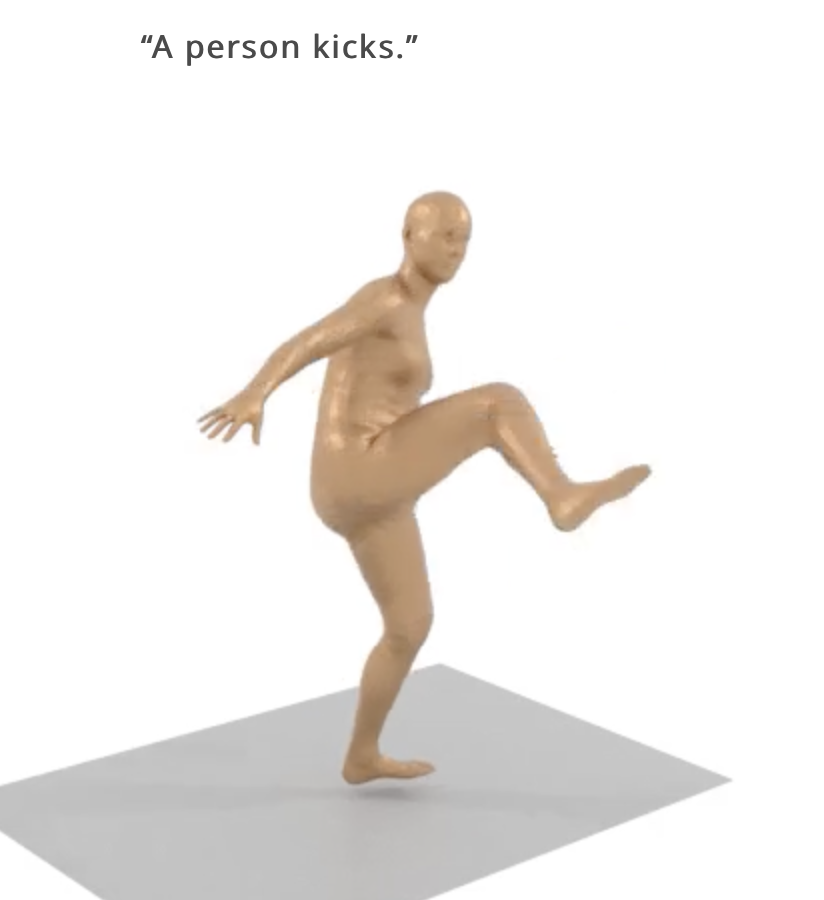
Text to animation
Just a few weeks ago, Text-to-Animation was being touted as the “logical next step” for the likes of dall-E 2 and MidJourney et al. Well in the fast developing world of AI that’s fast enough for a first demonstration! Meta has released a new AI tool to “Make a Video“. While these have been used to make animations for music videos, and sci-fi films the Text-to-Image tools lack temporal cohesion, i.e. they flicker every frame because the AI doesn’t remember what it did last frame!
Meta’s new tool has none of the inter-image/frame flicker of Text-to-Image tools. The examples on the Make a Video site are impressive. Another iteration or two and we’ll be using them in productions.
Text to Music
The Muber Text-to-Music project is a collaboration with Google, using Stable Diffusion (the same technology that drives text-to-image and text-to-animation) to generate music based on mood prompt and duration.
Text to “edit”
RunwayML.com, already known for their near-magic object extraction and fill AI tools, have announced a beta introduction of a tool to “edit video with natural language.”

Their teaser video isn’t editing as I would know it, but it is fascinating.
What is the end game if text prompts aren’t? Anything driven by text, can be driven by a “speech to text” interface. We are heading for “computer, draw me a blockbuster!” (Well, maybe not, but it’ll make b-roll a whole lot easier.)