I am uncertain whether digital actors and sets belong in production or post production! If there’s no location or actors to shoot, is it production at all? That philosophical discussion is for a future generation to decide, but digital actors in digital sets are here now.
We already have tools like Massive for simulating large crowds and background talent. Blue/Green screen keying is being partially supplanted by the LED Stage developed for The Mandalorian. Although not directly AI/ML related we’re at the tipping point between the various keying techniques pioneered 48 years ago with Mary Poppins’ Sodium Screen technique, and LED screens powered by tools like the Unreal Engine.
The future may in fact be Unreal! The Unreal Engine is the foundation of the Madalorian sets and environments, but it’s also the engine at the heart of Metahuman – very realistic, fully synthetic humans.

Actors have breathed life into ‘synthetic’ characters for years in animation. I expect we’ll see another generation of actors who power synthetic, but visually complete, “human” actors, thanks to the Unreal Engine. Metahumans inherit all the character animation tools in Unreal Engine. Check out the videos on the product page.
Unreal’s Metahumans aren’t the only synthetic humans on the horizon. While aimed at different markets, Neon are also creating realistic humans.
At a minimum, an increase in the use of Metahumans and similar developments, will allow actors to amplify their career beyond physical or age limitations. Actors could work from home by having a simple performance capture rig in their home office!

Synthetic actors will require human driven performances: for now. While I’m not aware of any research teaching a machine how to create an emotionally real performance, at the spokesmodel level, we are already there. Synthesia generates an “AI presenter” video from the text you type in!
There are digital presenters already in use, and covered later in this article. A related, also covered further into the article, is the field of foreign language dubbing that modifies the original actor’s mouth to match the new language, also in the original actor’s voice!
Thanks to ML we have a BBC newsreader deliver the news in English, and Spanish, Mandarin and Hindi, even though Matthew Amroliwala only speaks English! Japanese network NHK have gone one step further by dispensing with the newsreader entirely, to create “an artificially intelligent news anchor.”
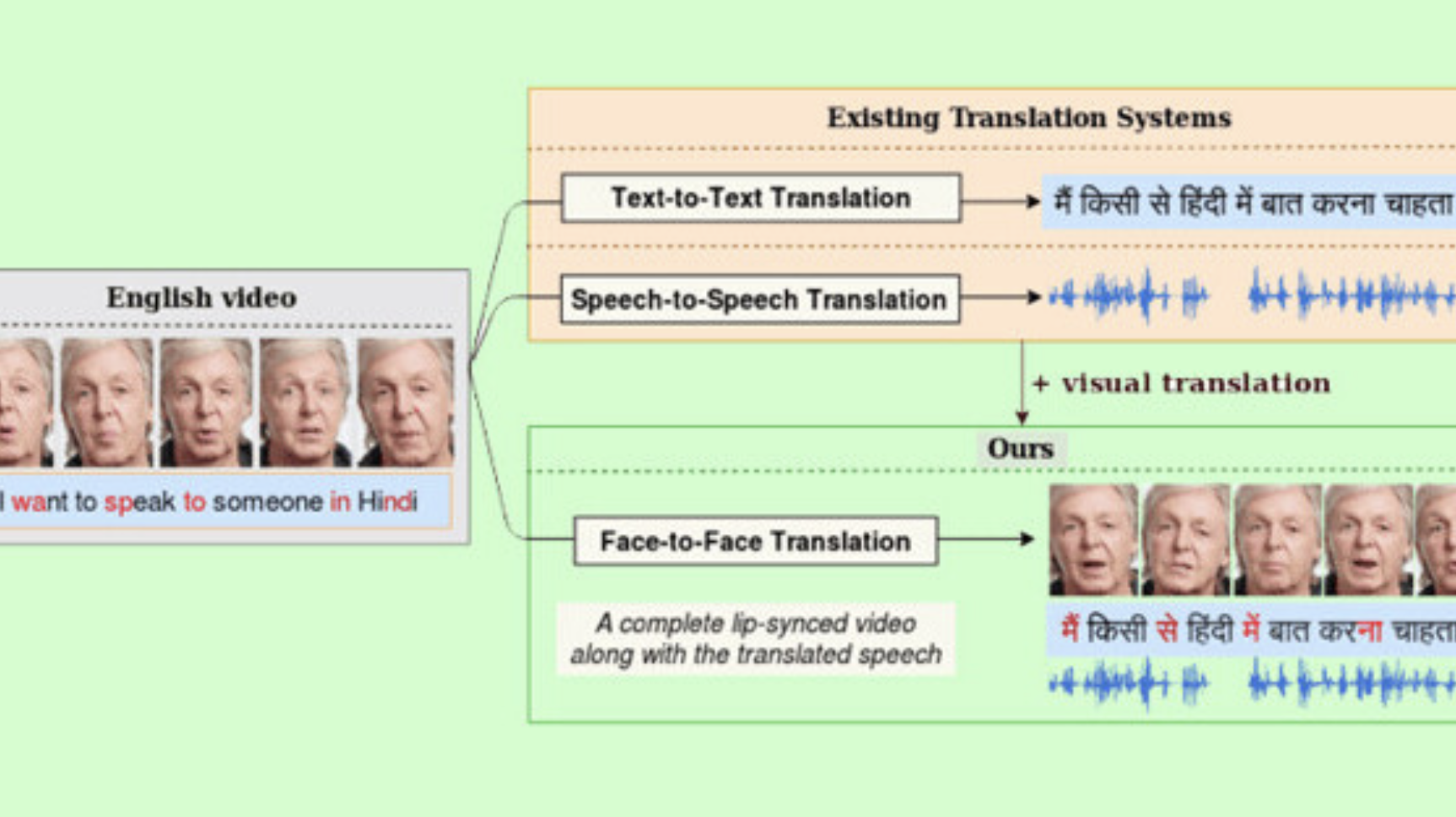
Another obvious application is in translation of movies into additional languages for foreign markets. Instead of human dubbing, the translation is automatic, the voice is cloned in the new language, and the lips morphed for the new lip sync! It’s not quite living up to that hype with a prototype that only works with a still image of the face, with good lip sync. The time will come when an evolved version makes any movie available in any language, believably! Even if you’re sending home movies back to family in the “old country.”
That leads us to deepfakes, as the examples so far have relied on some of the same techniques. Deepfakes can raise dead actors to star again, or convey birthday greetings from a long dead father. Of all the technology we’ve talked about, deepfakes are the most controversial.
Multilingual Newsreaders
Our first example is from the BBC, where London-based start-up Synthesia created a tool that allows newsreader Matthew Amroliwala to deliver the news in Spanish, Mandarin and Hindi, as well as his native English. Amroliwala only speaks English.
The technique is known as deepfake, where software replaces an original face with a computer-generated face of another. (There’s a whole section on deep fakes coming up.)
Amroliwala was asked to read a script in BBC Click’s film studio and the same phrases were also read by speakers of other languages.
The software, created by London based start-up Synthesia, then mapped and manipulated Amroliwala’s lips to mouth the different languages.

Researchers for the Japanese TV Network NHK have gone further and created a fully artificial presenter for news and live anchor roles! NHK’s application only creates a monolingual presenter, but it’s inevitable the two streams of research will merge. For now, here’s the summary of a research paper AI News Anchor with Deep Learning-based Speech Synthesis,
Kiyoshi Kurihara et. al. present a detailed discussion of how they use a deep neural network and speech synthesis to create an artificially intelligent news anchor. Their system is being used to read news automatically and for AI anchors of live programs on NHK. It is in use now and they hope it will serve as a model for other applications.
Translating and Dubbing Lip Sync
When I presented at an event in Barcelona in November 2016 I relied on professional translators to “dub” my presentation into Spanish for the majority of the audience. (They had reverse translators for us English speakers during the Spanish presentations.)
Translation and lip-sync issues plague movies and television shows as they move into new markets with a new language. The classic solution has been to overdub the voices with local actors, attempting their best at lip synching with the original, and failing terribly most of the time. Everyone is thankful my translators didn’t try to get any lip synch!
It’s unsurprising that researchers are applying ML to this problem, with some rapidly changing results. For example, this “AI” can perfectly dub videos in Indic languages — and correct lip syncing. Pretty impressive:
Researchers from the International Institute of Information Technology from the southern city of Hyderabad, India have developed a new AI model that translates and lip-syncs a video from one language to another with great accuracy.
While it can match lip movements of translated text in an original video, it can also correct lip movements in a dubbed movie.
https://cdn.iiit.ac.in/cdn/cvit.iiit.ac.in/images/Projects/facetoface_translation/paper.pdf
While my Portuguese is as good as my Spanish, I didn’t really need Google Translate to tell me that this article was “Deepfakes will be used to make actors’ lips match dubbing in other languages.”
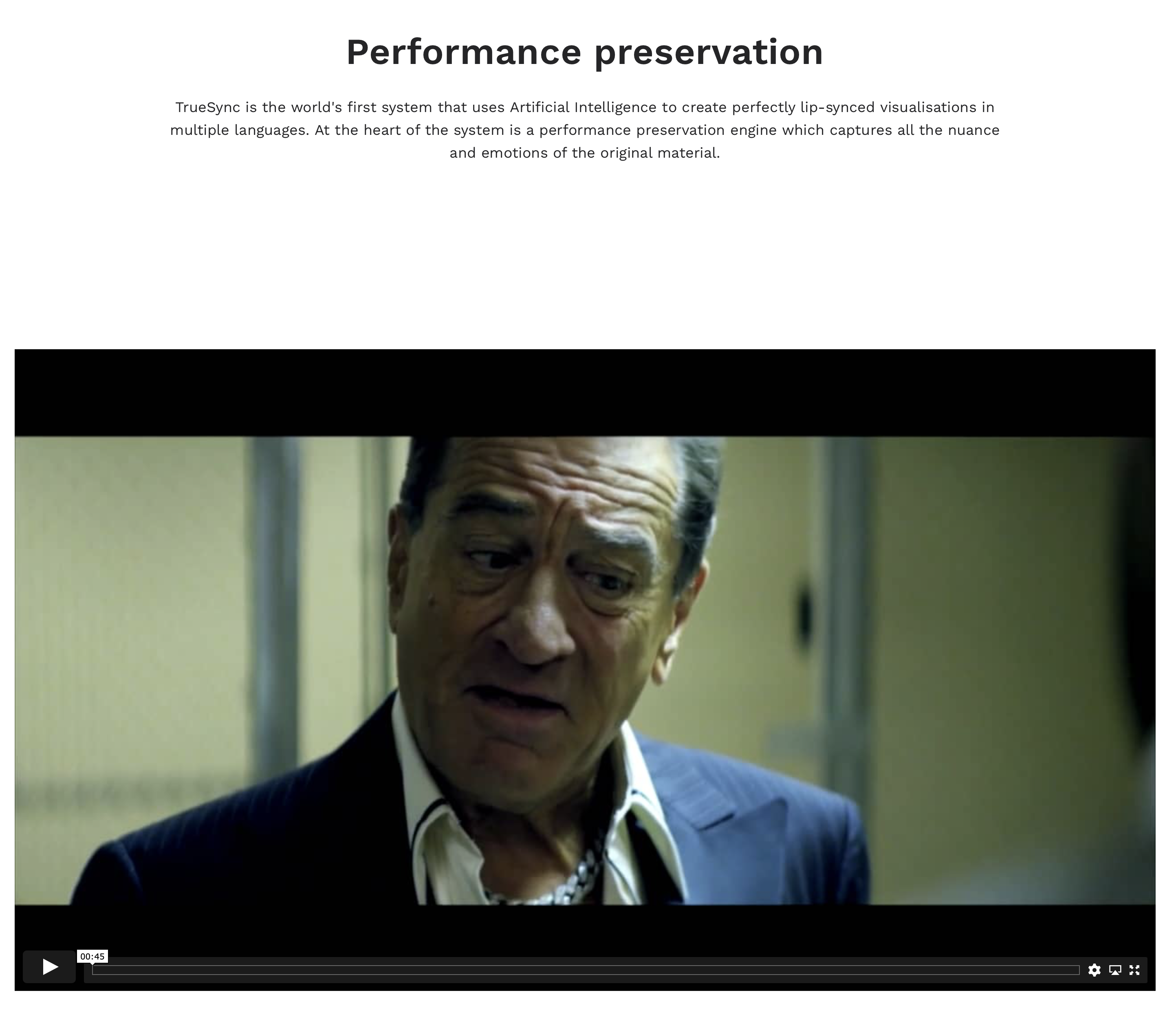
Another research project has Robert DeNiro delivering his famous line from Taxi Driver in flawless German with matching lip movements and facial expressions! Single lines for now, but in the sequence of writing this article, that was so “last week” (literally). Then I discovered a link to a company claiming to do seamless translation and lip sync across languages: FlawlessAI’s TrueSync.
The short sample on that page supports their assertion:
TrueSync is the world’s first system that uses Artificial Intelligence to create perfectly lip-synced visualisations in multiple languages. At the heart of the system is a performance preservation engine which captures all the nuance and emotions of the original material. .
Netflix is currently driving a resurgence in the art of dubbing. In an article from the end of March 2021, Bloomberg had a feature article: Netflix’s Dubbed Shows Turn Voice Artists Into New Global Stars.
As streaming services push programming from around the world, voice acting is a growth industry — and even Americans are embracing dubbing.
With a dubbing operation that vast, I’m sure there are research projects inside Netflix working on automating the process as much as possible.
While still at the research stage “LipSync3D: Data-Efficient Learning of Personalized 3D Talking Faces from Video using Pose and Lighting Normalization” shows the potential for automatically translating the dialog between languages, and matching the lips of the original actors to the new language.
Spokesmodels
I finished my first draft of this article in May of 2021, where I wrote:
Before you get to that (fully lip synched translation), you’ll see an example of a fully computer generated voice (from text) and performance of a digital actor to match. In this example, there is no performance capture required.
As an indication of just how fast these fields are developing, just four months later we have Synthesia. Synthesia generates a fully artificial “AI presenter” video from the text you type in! With forty “presenters” – avatars at Synthesia – and over 50 supported languages, it’s a bigger casting pool than I had available my entire career in Newcastle, Australia!

https://share.synthesia.io/41db521b-fcb6-4aa8-99bf-9f27484be286
Synthesia’s spokesmodels offer a moderately natural performance, quite good enough for corporate work. Synthesia’s spokesmodel are likely more natural than those on many local, late night TV ads!
Check out the quick demo I made using their default avatar.
Deepfakes
Wikipedia describes Deepfakes as:
… synthetic media in which a person in an existing image or video is replaced with someone else’s likeness. … deepfakes leverage powerful techniques from machine learning and artificial intelligence to manipulate or generate visual and audio content with a high potential to deceive.
Early in 2021, a deepfake (or many) of Tom Cruise started circulating on YouTube that are very believable. Vlogger Tom Scott also demonstrated just how easy it was to create a deepfake of himself for under $100!
Here’s a composite of a deepfake Tom Cruise.

It’s very believable, but not quite magic! The deepfake is the face. The body, as you can see in the making of video, is of a Tom Cruise look alike. We’re not turning Bruce Banner into The Hulk!
You’ll find dozens of examples of deepfakes with a simple search on YouTube. If I hadn’t, I’d have never known that Tom Cruise ran for President in 2020!
Deepfakes have already been used to create “Full on Apparitions of the Dead” according to Slate, for movies of course, but also for birthday greetings from dead fathers.
Joaquin Oliver died in the 2018 Parkland shooting, but he popped up in the 2020 political season urging people to vote. Technologies at Change the Ref:
…created a video of him speaking out against gun violence, which his parents could take to protests around the country. In the video, Oliver’s likeness says “I mean, vote for me. Because I can’t.”
https://twitter.com/ajplus/status/1321591323833454592
They needed to print the 3D model, to shoot on video, because these type of deepfakes usually require large numbers of samples of the target face. Samples of Tom Cruise are available in almost countless movies and TV appearances. Those samples did not exist for Joaquin Oliver, hence the 3D printed workaround.
Deepfakes are mainstream enough that there’s a “20 Best Deep Fakes” compilation video at YouTube. Although among the most disturbing must be this compilation of Star Trek TOS scenes with every character played by Jim Carey.
Creating a deepfake used to require deep pockets, as significant work is required, but it apparently doesn’t have to be. Educational blogger Tom Scott set out to create a deepfake Tom Scott. It certainly lacks the fidelity of the other examples on YouTube, but it should be kept in mind his budget was $100. And now DeepFakeKive will deepfake your Zoom or TikTok!

Disney have considerably deeper pockets as they “resurrect and revive dead actors” using deepfake techniques.
Disney Research Studios is spearheading the project, and they call it “the first method capable of rendering photo-realistic and temporally coherent results at megapixel resolution.”
Furthermore, this algorithm also will make “any performance transferable between any two identities” in any given database.
It’s a fascinating read, and you know if Disney Research is working on it, there are labs in every other major studio conducting technological seances to get dead actors back to work. Not to mention that the body double actors probably don’t command the same premium salary as the long dead star.
What is most intriguing about this project is that the “algorithm” makes performances transferable between any actors – living or dead! A modern actor’s performance would give life to the resurrected actor, much as Metahumans do.
In the short period between draft and final, the field of Deepfakes has moved on to the point that DeepFakeLive will do real time deepfakes for your Zoom, Twitch or TikTok. From expensive lab project to a real-time toy for your Zoom meetings in around five years, should be an indicator of the rapid pace of development with these tools.
However these tools end up being deployed, I feel confident that the foreign language experience is going to improve in the future. Perhaps I could finally watch Drag Race Holland without the distraction of subtitles.
Digital Humans and Beyond
I chose “humans” over actors deliberately, because while Metahumans look real, and are fully animatable in the Unreal Engine, but they are still powered by a human performance, much the way actors have breathed life into animated characters for generations.
While fully synthetic performances if fine for Synthesis’s Spokesmodels mentioned above, they fall short of the emotional impact of talented actors, even when the performance is tied to a non-human ‘actor’ as we see in the Digital Andy Serkis performance mentioned below.
Early attempts at animated ‘human’ characters, like in Polar Express, got lost in the ‘uncanny valley’ effect, where the more human the character is supposed to be, the more unreal it becomes. Except the ability to synthesize human faces has made massive strides in recent years thanks to Generative Adversarial Networks (GAN), which is one of the ways that ML can train itself.
Simply put, a GAN pits two machines against each other, so instead of requiring a huge training set, the adversarial machines train each other. For example, one machine will attempt to generate a human face, while the adversary is trying to detect human faces. Success (or not) is fed back to the original machine and the cycle repeats. Millions of times a second! You’ll find a much more detailed explanation at KDnuggets both about GANs and specifically generating realistic human faces.
There are more examples at ThisPersonDoesNotExist. It loads a random fake human each time.
Metahumans are the next advancement of that work. With ‘design your human’ tools that work by dragging sliders for how each feature should appear, they are extremely flexible, and very realistic. The Unreal Engine gives each Metahuman full animation capabilities driven by an actor’s performance. Although keep in mind that the performance and character are completely isolated.

On the Metahumans page at Unreal, one example is a digital Andy Serkis performed by the actor Andy Serkis. The digital version is very convincing, but click through to the details and you’ll find the same performance applied to 3Lateral’s Osiris Black!
This, like animation acting, should bring a lot more freedom to actors. 2021 Michael Horton, for example, could still star in the remake of Murder She Wrote as his younger self! The way Hollywood is, though, it will probably be used to impose new performers on the identity and image of long dead stars.
While creating new performances for these digital humans is going to be a much bigger challenge than the digital spokesmodels, I expect that performances will be sampled in the way visuals are sampled for deepfakes, then used to create new performances. It won’t be Academy Award worthy, but for Mike Pearl’s ‘Black Box’, it will be an essential component.
If your needs are more toward the spokesmodel instead of actor, then Synthesia let’s you choose your spokesmodel and then type in your text for a moderately natural performance, quite good enough for corporate work. Synthesia’s spokesmodel are likely more natural than those on local, late night TV ads!
Introduction, AI and ML, Amplified Creativity
- Introduction and a little history
- What is Artificial Intelligence and Machine Learning
- Amplified Creatives
- Can machines tell stories? Some attempts
- Car Commercial
- Science Fiction
- Music Video
- The Black Box – the ultimate storyteller
- Documentary Production
- Greenlighting
- Storyboarding
- Breakdowns and Budgeting
- Voice Casting
- Automated Action tracking and camera switching
- Smart Camera Mounts
- Autonomous Drones
Amplifying Audio Post Production
- Automated Mixing
- Synthetic Voiceovers
- Voice Cloning
- Music Composition
Amplifying Visual Processing and Effects
- Noise Reduction, Upscaling, Frame Rate Conversion and Colorization
- Intelligent Reframing
- Rotoscoping and Image Fill
- Aging, De-aging and Digital Makeup
- ML Color Grading
Amplifying Actors
- Multilingual Newsreaders
- Translating and Dubbing Lip Sync
- Deep Fakes
- Digital Humans and Beyond
- Generating images from nothing
- Predicting and generating between first and last frames.
- Using AI to generate 3D holograms
- Visual Search
- Natural Language Processing
- Transcription
- Keyword Extraction
- Working with Transcripts
- We already have automated editing
- Magisto, Memories, Wibbitz, etc
- Templatorization
- Automated Sports Highlight Reels
- The obstacles to automating creative editing
Amplifying your own Creativity
- Change is hard – it is the most adaptable that survive
- Experience and practice new technologies
- Keep your brain young