If you know me, you’ll know I’m a metadata nut. I’ve never metadata I didn’t like! For me this is both an extremely exciting time and yet somewhat disappointing.
We now have the tools for accurate transcription, extract text from moving images, identify objects in the video, extract keywords, concepts and even emotion, and that is all good.
In fact, for all types of searching, whether it’s in a project, or any form of asset management system, this metadata is awesome. Tools like FCP Video Tag make it possible to find that perfect b-roll shot in your FCP Library, or like AxelAI in your asset library.
Metadata is information about the media files. It can be technical metadata describing the file format, codec, size, etc, or it can be information about the content – what we also call Logging!
For discovery and organization we need the logging metadata to be concise and associated only with the range in the media file that it’s relevant to. One way to achieve that is to isolate subclip ranges and organize them in Bins associated with topics, or in Markers with duration.For me the perfect embodiment of Logging Metadata is Final Cut Pro’s Keyword Ranges, that self organize into collections.
I’ll be focusing on Visual Search and Natural Language Processing, but there are many commercial and open source tools for extracting or embedding technical metadata including Synopsis.video, which will also allow semantic searching of movies using terms like “an interior, closeup shot outside, in a vineyard with shallow depth of field”, and CinemaNet (part of the Synopsis set of tools) will understand and match because it has been taught to understand those visual concepts.
Visual Search
At the last IBC we were able to attend, we saw an IBM Watson pod that was extracting metadata about the content of a fast moving car race, on the fly. The car ID, any advertising on the car, any text on signs in the background, description of the background, etc. There was an avalanche of information being extracted in real time from this race footage. More on the avalanche in a minute.
The challenge with visual search is that most of these ML services are on the web, and uploading video is challenging, especially when it’s only for extracting metadata. Audio for transcription is practical as the bandwidth is a fraction of video. In fact some services require the media to already be in ‘the cloud.’ For example, Google Video search requires the video to be stored in Google Videos. From there it can be indexed, even programmatically from 3rd party apps, but first there’s the upload.
Then there are the silos. Google Video Search only searches videos online, YouTube searches within YouTube; Snapchat within Snapchat, and so on. Search Engine Journal has a run down. Every stock footage company has a visual search function, either using text to search indexed video, or to search based on matching an uploaded image!
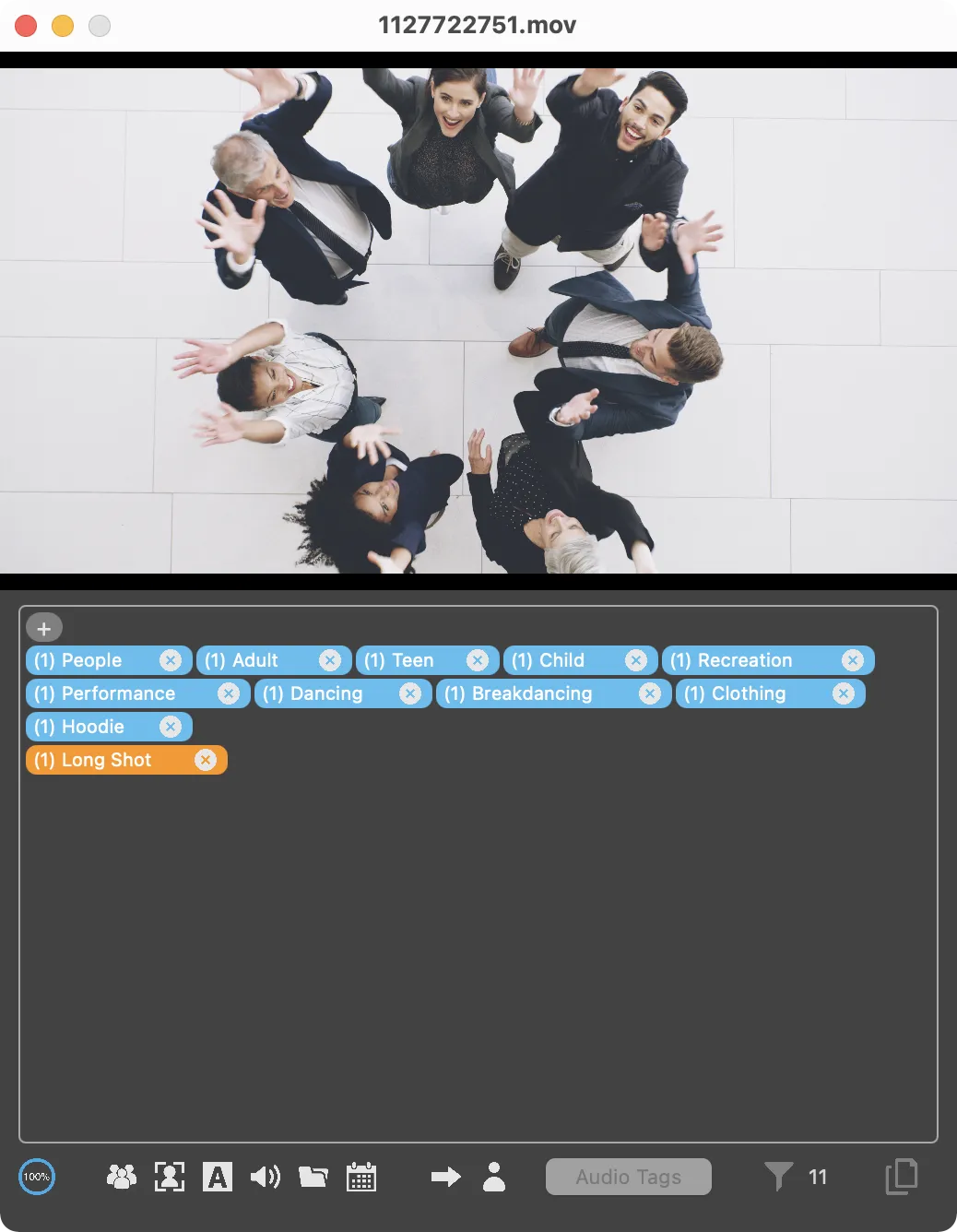
Visual Search has to be integrated with the NLE and not require an upload, to be really useful. Face detection and identification has been in Blackmagic Resolve since version 16, but not generalized video search, yet. I’ve seen technology previews of Premiere Pro that included integration with IBM Watson visual search that have never been in a released version. Technology previews aren’t a sign of future product, but they do point to the direction of a company’s thinking.
Adobe obviously plans extensive and flexible visual search:
In the near future, that may be time you get back. AI is already learning how to “view” images, recognize notable elements and layouts, and automatically tag and describe them. Taking this a step further, Concept Canvas, one of our Adobe Research projects, will allow users to search images based on spatial relationships between concepts
https://research.adobe.com/concept-canvas/
Until visual search is integrated into your favorite NLE, there are some interim solutions. Most major Media Asset Management systems include some form of visual indexing and searching. AxelAI, for example, performs all the analysis on the local network.
FCP Video Tag uses a number of different analysis engines to create Keyword Ranges for FCP in a stand alone app.
If you want to roll-your-own ‘video understanding’ engine, Facebook have a Framework for you to work with. Or integrate IBM Watson’s Visual Recognition tools in CoreML for macOS and iOS.
Natural Language Processing
Visual search is great when the primary thing we’re interested in is visual. When it comes to interviews, the only visual metadata that would be available for this image:
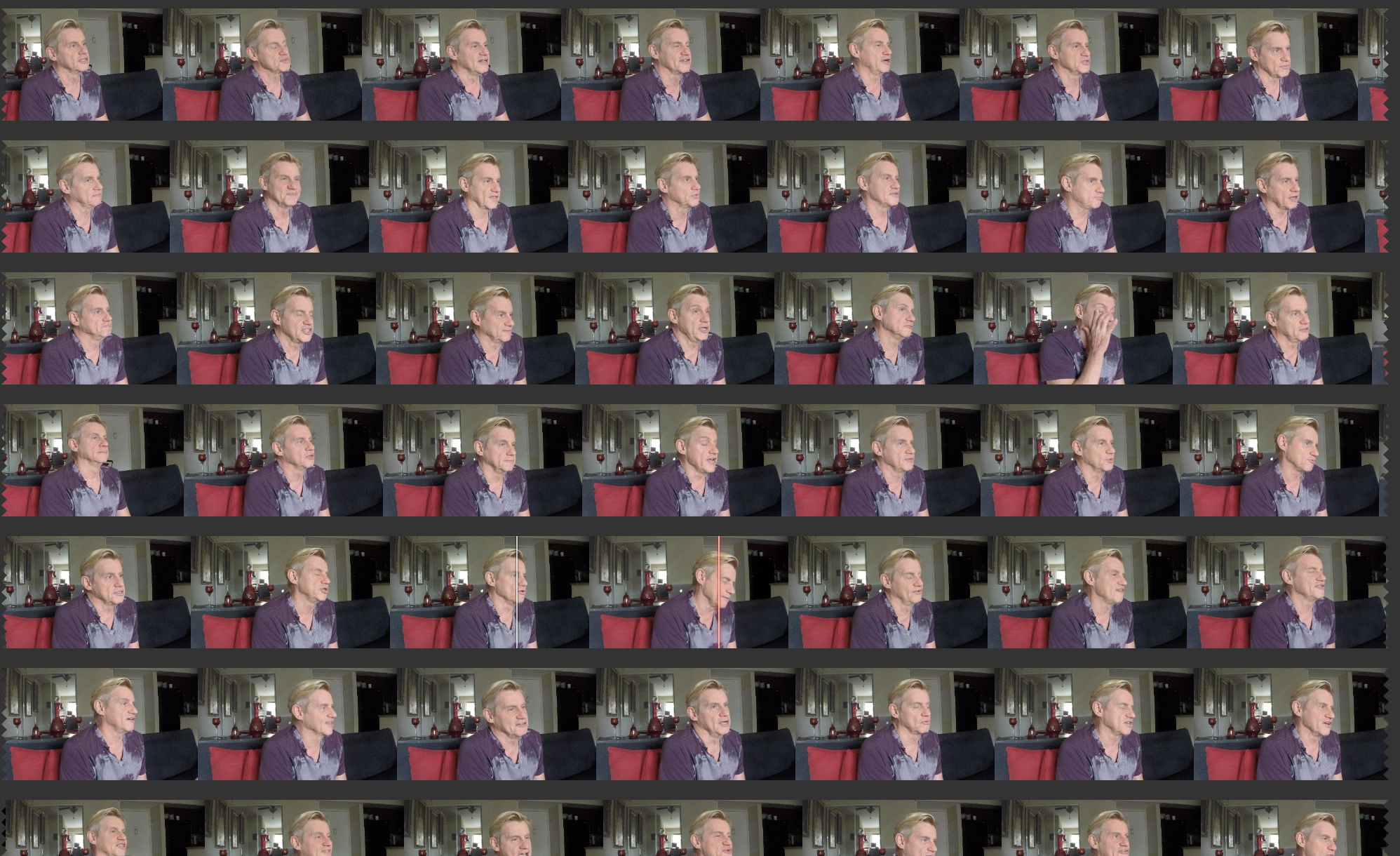
would be: Philip Hodgetts (although more likely “Middle Aged White Male”, which is a whole lot less useful); Medium Wide shot, Living Room. We would have no useful information about the content of that 30 minute interview. That is where Natural Language Processing takes over. Because it starts with transcribing speech, it could be thought of as the speech equivalent of visual search!
Transcription
Transcription, or speech-to-text is now a mature technology. I’ve watched the accuracy of our transcription provider for Lumberjack Builder NLE improve significantly in flexibility and accuracy since my original testing in 2018. In 2018 punctuation was perfunctory at best, a bad guess normally, and speaker identification was way off, but word accuracy was as high as 99.97% in one of my examples.
It’s now three years later and a recent test, ahead of re-introducing speaker identification to Builder NLE, accurately identified two very similar sounding female voices throughout the interview, with punctuation that would make an English teacher proud.
It’s just three years since we had unacceptable punctuation and speaker identification. Since then grammar and speaker identification are as accurate as the word transcription, which has also improved in that time, and become easier to use.
Accurate transcription arrived in a tidal wave of ongoing improvements, so when you are inclined to dismiss some of the technologies I’ve been introducing you to, remember it’s not where the technology is right now, it’s where it’s going to be in two to three years that will affect your career.
If a research project could lead to changes in the way your job will be performed, it’s good to know far enough ahead, that you can decide on the best way that it is going to be used to Amplify your Creativity, and employability.
Accurate transcription in most major languages is now a given. It is what we can do with that metadata that becomes more interesting.
In order to improve speaker identification, our provider has done some intricate work with spectral tone maps. In the absence of any visuals, it’s the only option.
A Google Research project in 2018 attempted to “better identify who is speaking with a noisy environment,” specifically a noisy environment of other human voices at the same frequencies and approximate levels! This is a much more challenging task than identifying when a voice changes in a two or three person interview in a (relatively) quiet environment.
They solved the problem the way humans do! In that situation humans are able to focus their attention on one or two speakers in a crowd using what is called the “cocktail party effect.” You can easily work out who’s speaking and what they’re saying: a microphone, not so much. Google’s researchers got their machine to look at the video and see who’s mouth was moving! Easy for us to do, again much more challenging for the machine.
The effort into accurately understanding speaker change and speakers identified is to have interview “chunks” that make sense for keyword and emotion extraction.
Keyword Extraction
We’ve been waiting for a good “keyword” extraction tool for a long time. In an earlier version the Lumberjack Lumberyard app, we used to extract keywords from transcripts. We pulled the feature because the keywords were rarely useful. To a machine a keyword is literally, a key word, and that’s a popularity contest! The words that appear most frequently become keywords, but may not represent the concept accurately.
They are rarely the Keyword that I would use to describe the “content.” In my Builder NLE demo I work with media from EditStock where one of the major themes is Climate Change. Those words rarely appear and almost none of the discussion about Climate Change is tagged by automatic keywording.
MonkeyLearn specializes in extracting from a transcript and has no input into the transcription process itself. You have to create a free account to access it, but their Keyword Extraction tool gave these results from a paragraph from that Climate Change project.
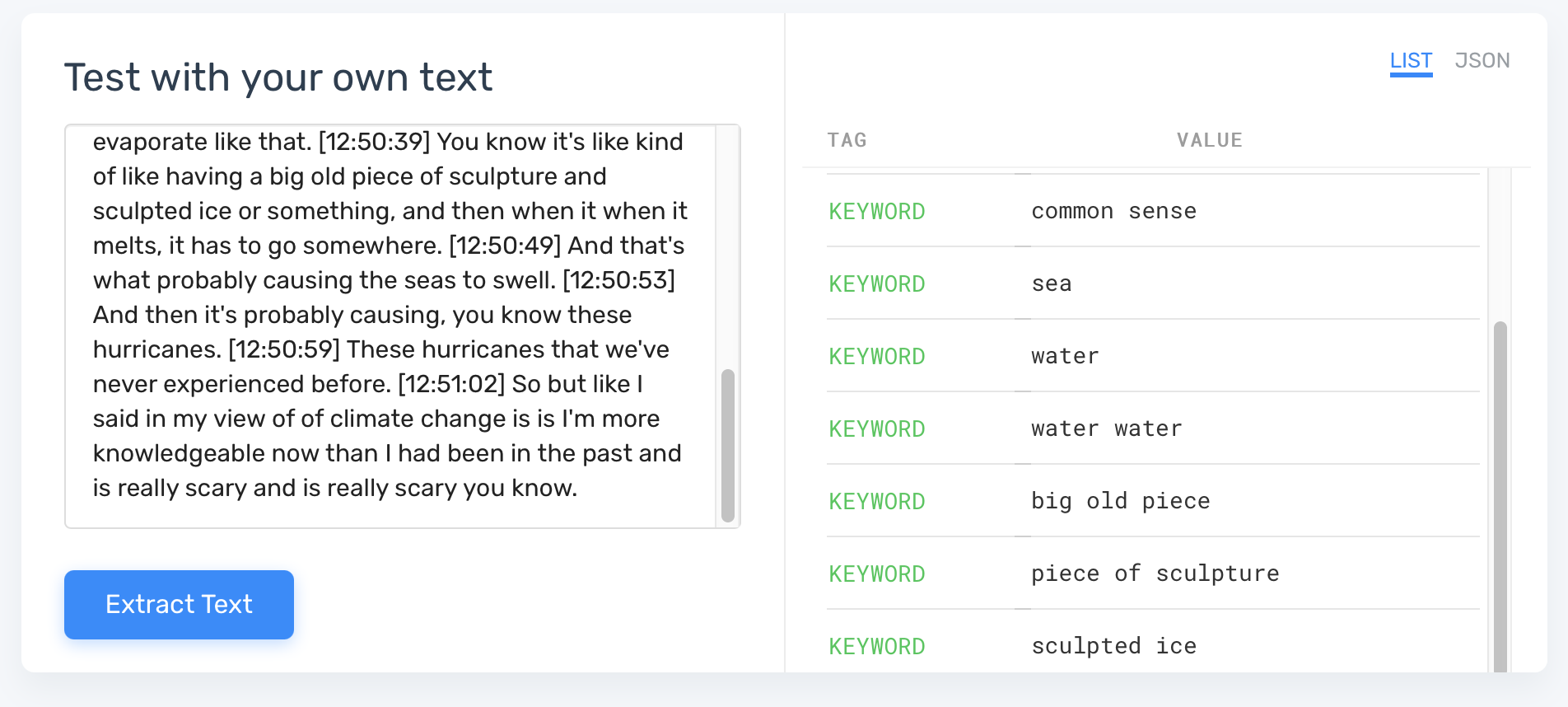
For reference, my Keyword was Climate Change, which was certainly in the results, along with another nine ‘keywords’ that weren’t useful. A 10% accurate tool, where you can’t predict which 10% is right, is unlikely to be a useful production tool.
IBM Watson does a little better with Keywords by providing a relevancy ranking. If you are a Lumberjack Builder NLE user, you might have noticed a relevancy column in the Keyword Manager. We included that with the expectation we’d be offering automatic (useful) Keywords by now where the relevancy would help rank (and remove) Keywords. It remains unused.

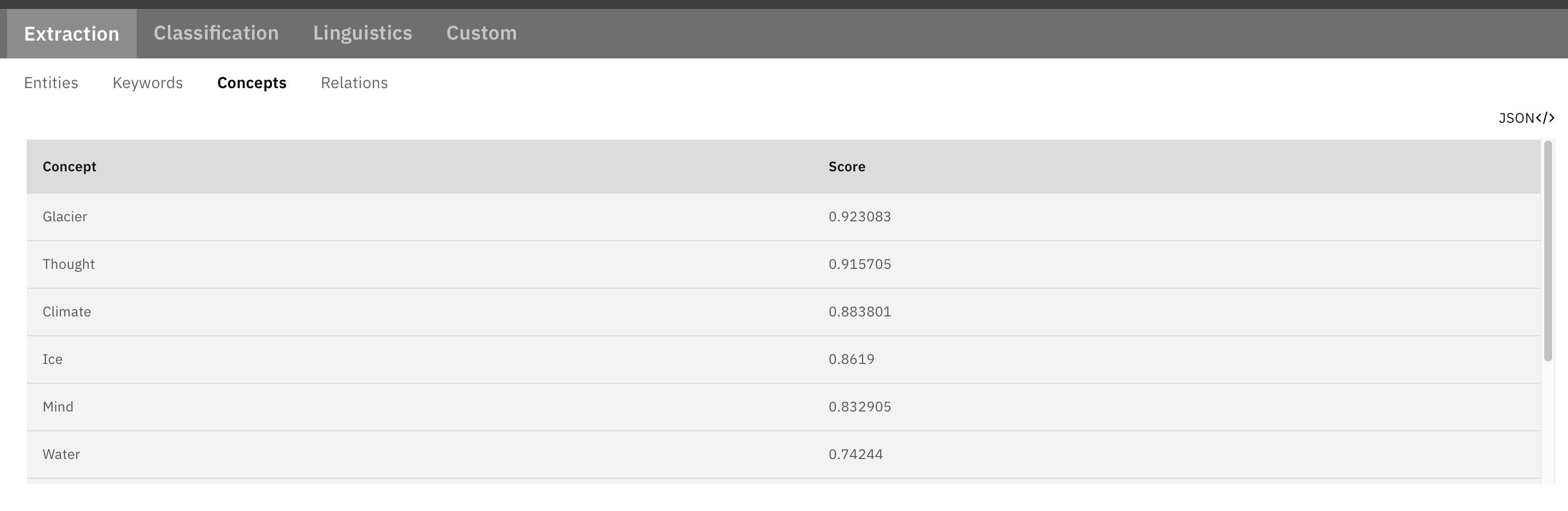
Watson also has the ability to extract Concepts, which is much closer to what we need for organizing and analyzing interviews. While Climate is discovered as a concept, Climate Change (the Keyword I used) does not appear. As with Keywords, there are nine or ten unhelpful Concepts in with the useful one(s).
As far as automated extraction of useful keywords for organization (as opposed to searching where the Visual Search is very useful) it’s simply not here. Yet! Until the technology moves forward, the most efficient way of logging/keywording is to do it in real time during the shoot with Lumberjack System’s iOS Logger, or with any of the other tools in the Lumberjack Suite. The second fastest way to log or keyword is using the transcripts in Lumberjack Builder NLE.
I thought that Tone Analysis – how happy or angry the speaker is – would be a useful tool, particularly for Reality TV where high emotion is an essential ingredient! Unfortunately Tone Analysis has the same need for human curation, that makes it a net negative in production!
Working with Transcripts
No mainstream NLE is a good way of working with transcripts. There are many ways to get transcripts into various NLEs but none of them are a good environment to work with transcripts because nowhere can you actually write the story.
Before the digital era, and well into it, a story writer would take all the text documents of the transcripts and copy/paste into a story document, that some unfortunate editor had to conform. There’s nothing akin to the word processor text in NLEs. I include Avid’s ScriptSync in this blanket condemnation! ScriptSync is a useful tool for finding and comparing takes in editing narrative (scripted) content, but pales next to Builder NLE for editing with transcripts.
There are only two apps that take working with transcripts seriously: Descript and Lumberjack Builder NLE. Descript is positioned directly at podcasters and single take presenters, with a suite of tools that suit that market very well.
Builder NLE is the result of our frustration with the best we could do bringing transcripts into Final Cut Pro Classic back in 2010, and in Final Cut Pro X in 2014. While there is some utility in finding words in transcripts in the NLE, we hated the experience and knew we could do better since we are in the software business.
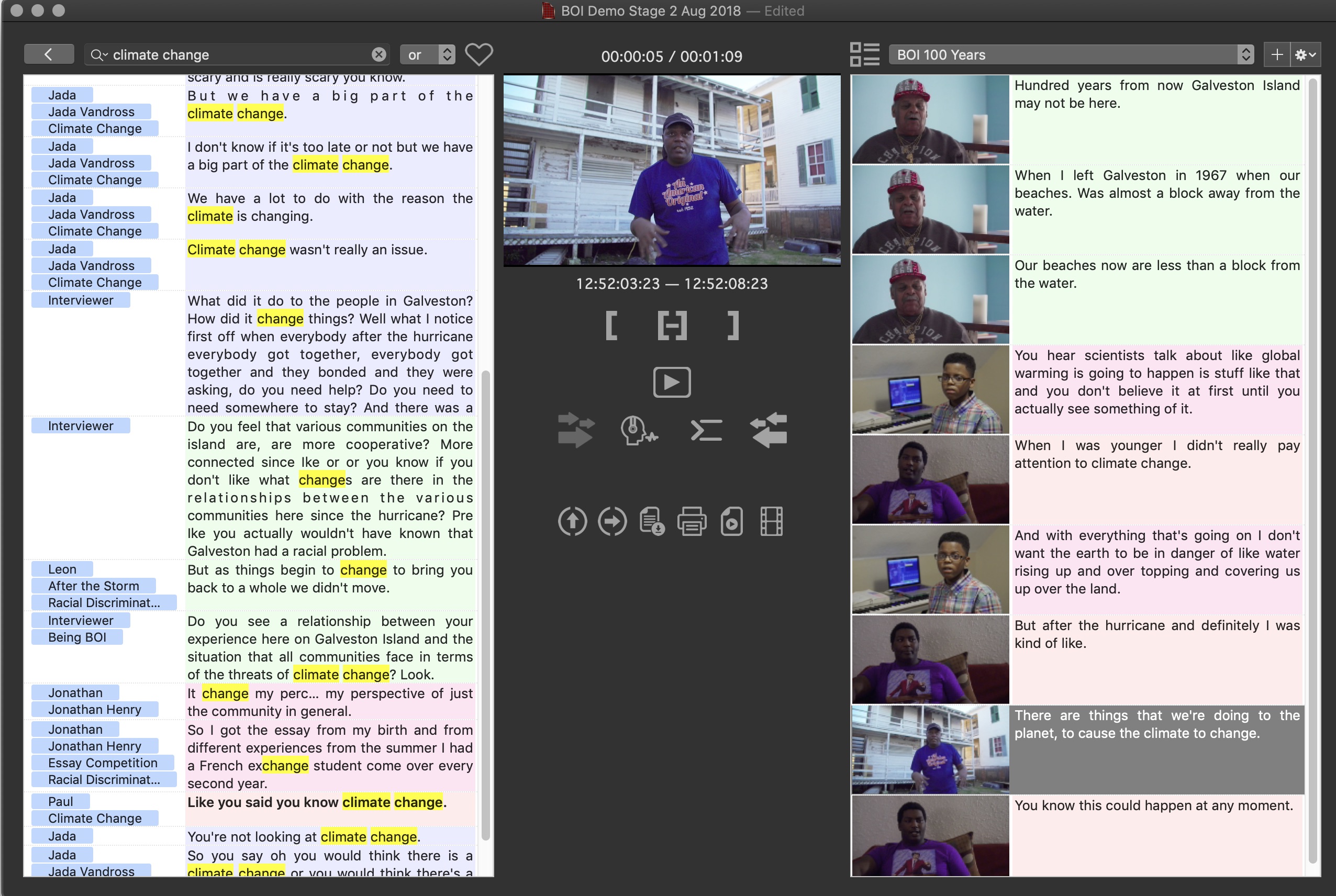
That is why we created Builder NLE as a hybrid word processor and video editor to take advantage of the abundance of accurate and inexpensive transcripts.
Maybe we will have automated, useful Keyword extraction from transcripts for organizing one day. I expected we would have by now, but I remain disappointed. Transcripts in the right environment are the second easiest way to add Keywords, and the foundation of amplified story telling, but for the moment those Keywords are going to be manually entered.
Visual search will become ubiquitous in NLEs over time and is an incredibly valuable tool for finding specific visuals.
Introduction, AI and ML, Amplified Creativity
- Introduction and a little history
- What is Artificial Intelligence and Machine Learning
- Amplified Creatives
- Can machines tell stories? Some attempts
- Car Commercial
- Science Fiction
- Music Video
- The Black Box – the ultimate storyteller
- Documentary Production
- Greenlighting
- Storyboarding
- Breakdowns and Budgeting
- Voice Casting
- Automated Action tracking and camera switching
- Smart Camera Mounts
- Autonomous Drones
Amplifying Audio Post Production
- Automated Mixing
- Synthetic Voiceovers
- Voice Cloning
- Music Composition
Amplifying Visual Processing and Effects
- Noise Reduction, Upscaling, Frame Rate Conversion and Colorization
- Intelligent Reframing
- Rotoscoping and Image Fill
- Aging, De-aging and Digital Makeup
- ML Color Grading
- Multilingual Newsreaders
- Translating and Dubbing Lip Sync
- Deep Fakes
- Digital Humans and Beyond
- Generating images from nothing
- Predicting and generating between first and last frames.
- Using AI to generate 3D holograms
Amplifying Metadata
- Visual Search
- Natural Language Processing
- Transcription
- Keyword Extraction
- Working with Transcripts
- We already have automated editing
- Magisto, Memories, Wibbitz, etc
- Templatorization
- Automated Sports Highlight Reels
- The obstacles to automating creative editing
Amplifying your own Creativity
- Change is hard – it is the most adaptable that survive
- Experience and practice new technologies
- Keep your brain young