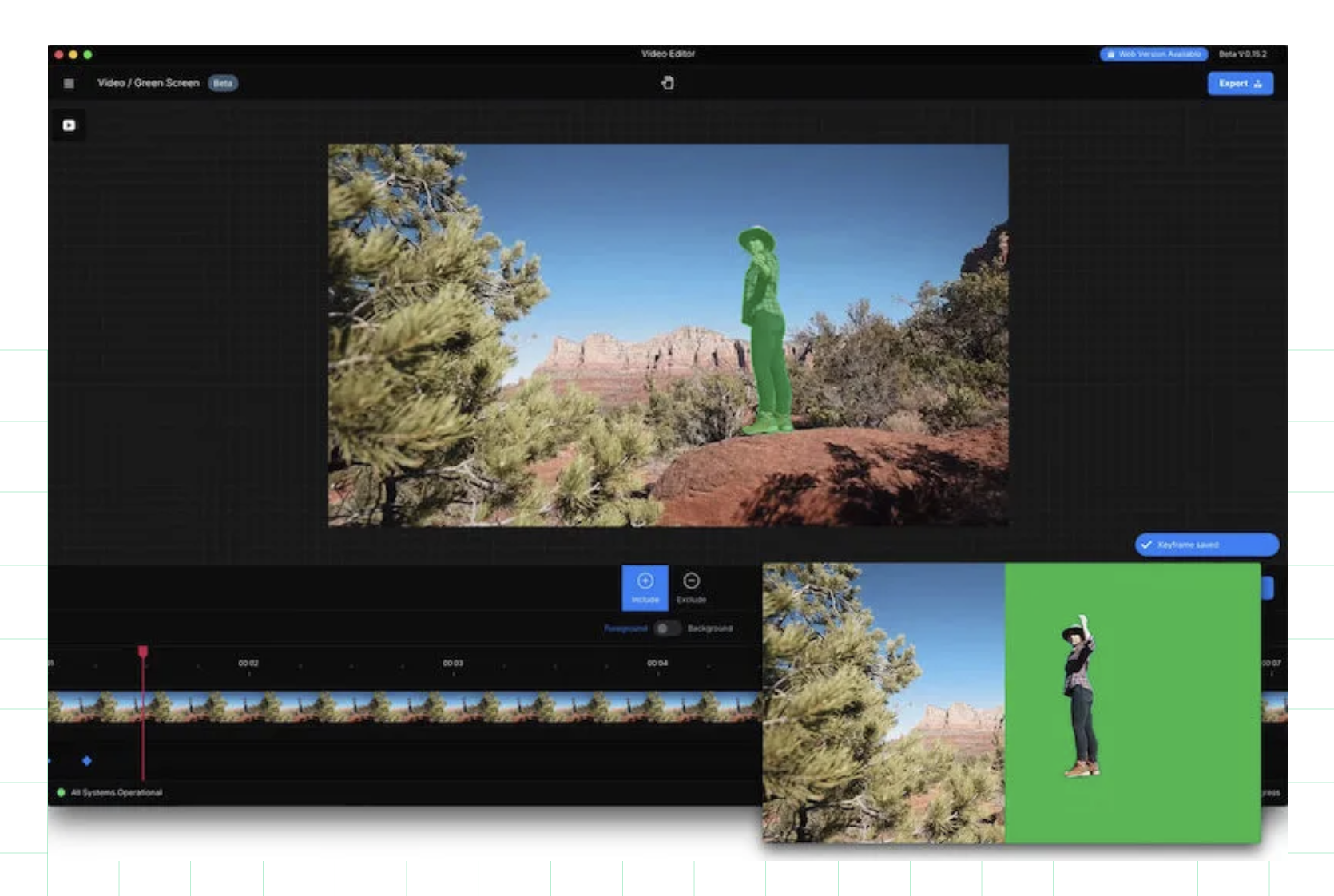
If I were staring my career now, I’d be focusing on Artificial Intelligence and Unreal Engine. One for making me more creative, and one opening a whole storytelling universe “on my desktop.” Given that I focused on post production because it had air conditioning, being able to control my “shooting universe” in air conditioning is definitely appealing. Unreal Engine has become a standard cinematic storytelling tool, and now with Netflix’s Validation Framework for it, it had de facto approval. Netflix have used Unreal Engine on 1899 and Super Giant Robot Brothers among other.
A Validation Framework not only ensures that all settings are correct and included files included, but also includes a support system to guide users through correcting any errors. And because I can, I’ve included a couple of Unreal Engine Cinematic examples.
Netflix has approved Unreal Engine on more than the productions noted above, and each iteration has been a learning experience, but one where each production has been “starting over.” With so many settings and permutations it’s easy to get the deliverables wrong. Enter Netflix’s Validation Framework for Unreal Engine, which is a plug-in for the app.
You can read the specific benefits from the framework in their blog entry.
15 Graphic Demos
Take a look at a representative sampling of the cinematic potential.
The Matrix Awakens: An Unreal Engine 5 Experience
A “fan fiction” Matrix experience rendered in Unreal Engine. These examples render in real time on modest hardware like X-Box and Playstation, which is why its very popular for revisualization. This particular example shows the (current) limitations on Metahumans. They are very driven by the performance capture.
It’s an extended example which shows some of the cinematic possibilities of Unreal Engine. Like every creative endeavor, the level of finish and realism is driven by the skill of the creatives.
Speaking of Metahumans
There’s an obvious attempt at a Metahuman Neo in the Matrix Awakens experience above, it’s harder to recreate a person than create a completely fictional character. Here’s an example of Hermione Granger Made Using Unreal Engine 5.
If you want to see more of what Unreal Engine is doing in the cinematic space, search Unreal Engine Demo on YouTube and you’ll find dozens of examples.
Whether or not Artificial Intelligence can ever be creative is an ongoing question. In the Unreal blog they highlighted a project Words, camera, action: Creating an AI music video with Unreal Engine 5. As is usually the case with creative projects, it was a collaboration between human creators and a multiplicity of Machine Learning ‘algorithms’ used primarily to apply looks.
If you’ve used Final Cut Pro, Premiere Pro or Blackmagic Resolve you are already using some Artificial Intelligence/Machine Learning tools. Final Cut Pro is catching up with the others in their use of Machine Learning tools in their NLEs. It’s likely that some of these stand alone tools, or features from them, will migrate into an NLE near you, but in the meantime here are five amazing tools you could/should be using now.
Automated Rotoscoping
Rotoscoping tools have been consistently evolving and improving from the days of b-splines in Commotion, to todays’s Rotobrush 2 in Adobe After Effects, but it remains one of the most tedious post production tasks, well suited to Machine Learning. RunwayML‘s approach uses an object recognition approach for both object extraction and background fill. RunwayML uses a monthly subscription based on output format: p to 720P output is free and 1080 output is just $15 a month. ProRes and 4K output is $35 a month and is apparently their most popular subscription.
Custom Music Creation
One of the technologies I was in awe of when I was a more active editor, was Smartsound’s Sonicfire Pro, which customized music tracks to match a specified video length. Very clever stuff that indeed was invented there. Having experienced Sonicfire Pro when I came across Soundraw it was immediately familiar.
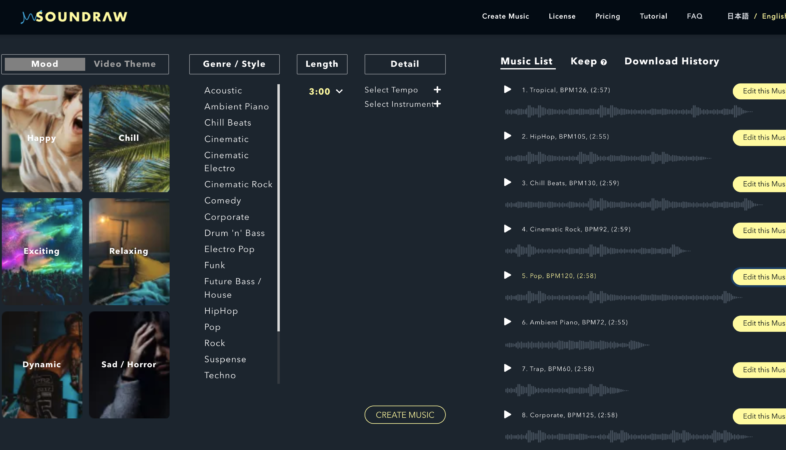
In Soundraw’s interface you choose a Mood or Video Theme, Style, Length and Instruments. In about 15 seconds Soundraw will generate 15 new, original and unique tracks for you. Choose one to edit and you have even more control over tempo, key, instruments and mix. You can load a video to synchronize with.
Soundraw’s durations lack the precision of Sonicfire Pro as they only increment in 30 or 60 second intervals, but for royalty free music I’ll take it. Two plans from $16.60 per month.
Soundraw created these 15 tracks for me in about 15 seconds.
Royalty free and unique custom models that have never existed
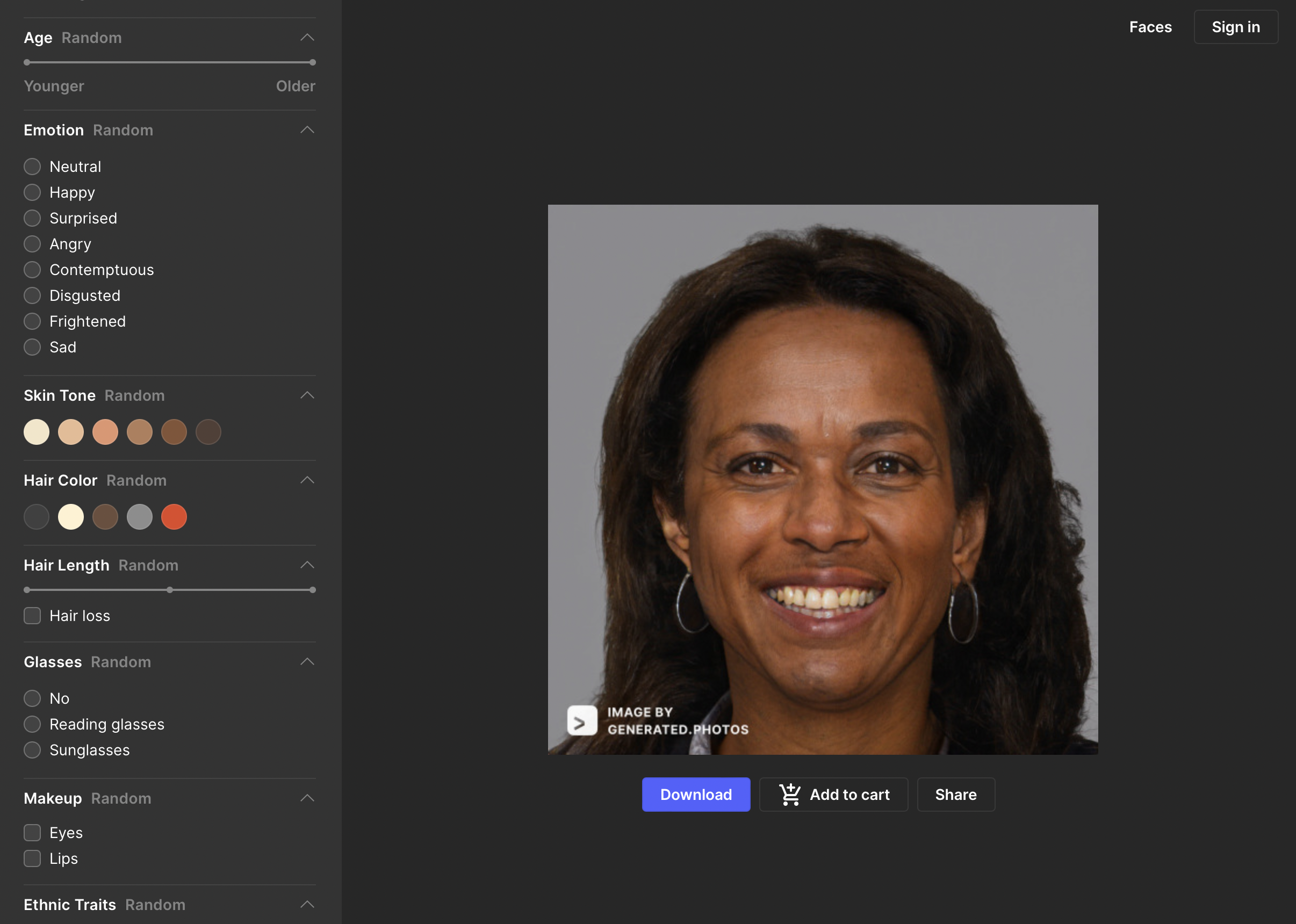
One way to avoid being busted using Stock Images to populate your advertising campaign, or to fill a bit of b-roll, is to make sure you never use a photo of a person. Enter Generated Photos where every face is unique and completely fake! You have complete control over how diverse you want your fake population.
The mainstay of many production business is the “talking head” shoot, which require organizing the on-camera talent, gear and crew, and a location. Not every “talking head” shoot is for something wonderful. More often they are fairly basic corporate communication or for education, and often melded with a PowerPoint style presentation. Synthesis.io takes your text input – typed or pasted in – and animates one of their many Avatars to speak that text.
Lumberjack System is using Synthesis.io to replace me in social media and help videos. It typically takes me about 5-10 minutes to set up and preview the audio and about 15 minutes for a rendered two minute video. The base plan allows for 10 minutes of video for $30 per month.
Here’s an example of a version one Avatar, which are pretty good, but you will see minor “uncanny valley” moments if you watch closely. They are rolling out there “more natural” version 2.0 avatars at the moment, but I haven’t yet experienced them yet. One nice editing feature is that all sentences start and end on the same frame with the new version! If only our real world presenters would be so consistent!
AI Studios is a new competitor to Synthesia.io while Rephrase.io takes a similar technology but to modify the one presentation to customize to thousands of unique videos.
When I drafted my Becoming an Amplified Creative article in May last year, I predicted that something like these Avatars was coming in “2-3 years.” In my pre-publication revision three months later, I had to include Synthesis.io and two months after that, I was a customer! This technology is evolving rapidly and it won’t be long before they are indistinguishable from live shoots with humans.
In all cases, these are real people who have been “sampled” in 10 minutes of video before being processed into the Avatars. There are dozens of Avatars and over a hundred languages. All performers have given permissions and were compensated according to the Synthesis.io.
“Computer, enhance”
Visual processing is where Machine Learning has made the most advances.Research Papers – technology developments not yet products – can regenerate faces in great detail from very low resolution or damaged inputs, fill in detail to upscale images much more. Topaz Labs have released tools for upscaling and de-noising that are invaluable for documentary work, where the originals often leave much to be desired in a 4K world!
Their Video Enhance AI not only upscales, but de-noises, de-interlaces, does some restoration and frame rate conversion. At US$200 it seems like magic to someone who started with ¾” quality! Adobe Camera RAW edged out Video Enhance AI for upscale quality in an A.I. Upscaling Software Shootout at Pro Video Coalition.
I just got back from Montreal with my brain full of thoughts about AI. Sharing these with you and looking forward to your reflections. Please feel free to comment back!
When Frame.io introduced Camera to Cloud I thought it was brilliant, but the level of technology that was required to implement it, led me to think that it was only for the “high end” of production, an area out of my experience. While often lucrative, that’s a fairly finite market, and I doubted C2C would ever be something I’d use. The (mis)belief that they were addressing a fairly limited market led to a little surprise with the Adobe valuation.
Three new tools use Machine Learning tools to compose music. Two with a gamified interface for free form composition, and the other a browser based custom music track creation tool, reminiscent of SmartSound, but with computer instruments.
ToneStone describes itself as a :musical creativity platform for everyone” and appears to be browser based. I say “appears” because I didn’t sign up for a trial. In their introductory video they describe using ToneStone as being “game like”.
The other gamified app is Vinyl Dreams on iOS describes itself as:
An innovative app that enables you, beginner or expert, to create high caliber productions anywhere, with just your fingers, eyes, and ears.
While I also chose to not invest the time in Vinyl Dreams or ToneStone, I did spend quite a lot of time with browser-based Sondraw, which creates custom-composed tracks. You set Mood, Genre/Style, Tempo and the general instrumentation, then within about 10 seconds Soundraw presents 15 tracks to your specifications!
The results are at least as good as library music I’ve paid money for in the past, although there is a slight “electronic” feel to the results.
The results can have further customization of instrumentation and which part are playing, on a segment by segment basis. You can even upload a video to preview the music against for timing and instrumentation. And it’s all done by Machine Learning.
The amazing thing about Soundraw is that we are at the point where it’s easier to get 15 custom composed tracks than pull up a music library online!
I recently read the article Art Created By Artificial Intelligence Can’t Be Copyrighted, US Agency Rules, which is an examination of the ruling by the US Copyright Office refusing to grant copyright to “creations” by an AI/ML: in this case images created by a Machine. These were deliberate test cases to determine the possibility of copyright and under what circumstances, but the Copyright Office “requires human authorship” in order to be granted copyright.
The test cases are important because there’s already a lot of money involved in the sale of the Machines’ creations. The article quotes the sale of one AI-authored ‘painting’ that sold fro $432,000, as a example.
My first response was to approve the Copyright Office ruling: it resonated that copyright had to have human involvement.
But then I considered the arguments being presented for granting copyright to the owner of a ‘creative’ Machine. It was argued that the owner of other types of machine were the owners of the output of the machine, and that’s quite valid. It almost swayed me for a moment, then I realized the fundamental difference is that other types of machine are churning out identical copies of the required output. There is no pretense that there’s anything creative in the output.
Even without copyright protection, people sell the output of all types of machines. The plaintiffs argument that they need copyright to control the use of the material (and make the most money from it) is somewhat undermined by arguing that the copyright should be in the owners’ names instead of the Machine to get around previous rulings of copyright ownership cited in the article.
Which bought me to my moment of outrage: “Why does every item of creative output have to be monetized?” The purpose of copyright is to provide limited protection for a limited time. It’s not designed to give perpetual ownership to an idea (a lesson Disney refuse to learn). It’s good for a culture when ideas can be shared and remixed into something new. Copyright control that’s too tight stifles this remixing and the society is lessened by it.
Given that the Machine can produce infinite numbers of “unique” creative works would likely undermine any potential value because of over-supply.
The deeper question is whether or not every item of creative expression has to be monetized. There’s an underlying assumption in the reporting on the ruling that everything should be monetized and there’s a deficiency somewhere when it cannot be. And that was my moment of outrage.
Storytelling has always been about painting pictures – in people’s mind or on a screen somewhere. One of the significant challenges for visual storytellers is creating the people and places from the storyteller’s imagination, into a more tangible medium, like digital bits! Artificial Intelligence (AI) and Machine Learning (ML) are dramatically simplifying the way we create our visual illusions.
While NVIDIA’s Canvas isn’t reading minds, research projects suggest we are moving toward being able to capture images from brain waves, or even hear internal voices. These research projects are a very long way from the premises of that first sentence, but advances happen so quickly it won’t be long before they move out of the lab into our creative process.
One of my deep regrets is that I have no native sketching skills, nor have I taken the time to learn, so it’s always a challenge when I have a mental picture that I’d love to visualize. Enter NVIDIA Canvas, which turns “simple” brush strokes into realistic landscape images.